
12週にわたり「”実践”システム障害対応」と題して、システム障害対応の改善のプロセスを約3か月で実行できるように、各週ごとに何を実践すればよいか?を考えていきたいと思います。
1週目では、「アラート・故障申告」の棚卸がなぜ大事なのかについて、以下3つの考えをご説明させていただきました。
■なぜ棚卸が大事なのか
- ユーザーの業務影響を極小化し、早期に業務を復旧できる可能性が高まるから
- .顧客の利益につながるから(まだ見ぬ大きなコスト削減になる)
- 属人化の防止、各インシデントの対処ナレッジが溜まるから
また、「記録されていないものこそを洗い出す」ヒアリングの中で新たな課題発見や棚卸し項目が見つかる可能性があることをご説明させていただきました。
2週目は、1週目で洗い出した「アラート・故障申告」の分類について考えていきましょう。
何を、どんな目的で分類をするか?
洗い出した「アラート・故障申告」を分類するにあたり、最初に目的を明確にすることが大事です。
私は大きく2つだと考えています。
ひとつは、アラート・故障申告が発生した際に、対処内容や体制/担当者を決めるための分類「緊急度・インパクト(影響度)」です。
もうひとつは、改善アクションを決めるための分類「「アラート・故障申告が無い状態」に向けた段階」です。
緊急度・インパクト
まずは、アラート・故障申告の影響の大きさを分類すべきだと思います。
以下は、緊急度とインパクトの一般的な一例とレベル定義の一覧となりますが
こちらは各サービスにあわせて決める必要があります。

一部の方は、この緊急度とインパクトの組み合わせで「SEV(Severity): 重大度」を決める事もします。
以下サンプル的な一例となりますが、「1」が最も重大だとした場合に「高」と「中」の組み合わせを一律にするのではなく、自身のサービス特性「大事な業務は何か?」から決める必要があります。
そして組み合わせた結果で矛盾がないか確認する必要があります。

緊急「高」でインパクト「高」であれば、休日であろうが祝日であろうが、深夜であろうが、必要な体制を決めて、対処を行っていく必要があるでしょう。
たとえば、インパクト(影響度)が高い場合は、サービス責任者へ(サービスとして責任を負える方)エスカレーションが必要になってきます。
指針として、「どのレベルであれば、誰まで連絡する。」という事が決定すると、いざ故障が起きた時に「どこまで連絡するべきなのか?」と悩まずに済みます。
また、方針として「悩んだら連絡する」「連絡を受けた人は、間違っていても相手を非難してはいけない」という文化があれば尚いいと思います。
「アラート・故障申告が無い」状態に向けた段階
緊急度やインパクト(影響度)は一般的な分類となりますが、私として「改善アクションに向けた分類」も追加すべきだと考えています。
アラート・故障申告を最終的にどのような状態にするのが良いのかと考えると、理想は「アラートも鳴らず、故障申告も来ない」が一番良い状態です。
私自身も現場に居るとだんだん麻痺してしまい、日々アラートがなり・故障申告があることが当たり前になってしまっていますが、それでは「ゆでガエルの法則」になります。
最終的に「アラートも鳴らず、故障申告も来ない」が一番良い状態」という事を忘れず意識するために、この分類が必要だと考えています。
といっても、いきなり一足飛びに進めるのは現実的では無いので、段階を経ながら徐々に改善していく必要があります。
そのため、最終的な「アラートも故障申告も無い」状態に向けて、どのような段階があるかを分類すべきだと思っています。
サーバ・アプリケーションとか、バッチ・オンラインなどの分類ももちろん大事かもしれませんが、システム障害対応をよりよくするためには「次何を改善していくか?」がわかる必要があります。
アラート・故障申告はどのような段階を経て良くなるか?
対処不要なものと対処必要なもので、改善アクション分類を考えてみたのが以下になります。
対処が不要
┗①-1対処不要と都度判断
┗①-2対処不要と自動判断
┗①-3アラートを停止(そもそもアラートが鳴らない)
対処が必要
┗②-1対処要と都度判断・内容を都度判断
┗②-2対処要と自動判断、対処内容は都度判断
┗②-3対処要と自動判断、定型的な手順で対処 :ワークアラウンド
┗②-4対処要と自動判断、自動実行 :自動復旧・オートヒーリング
┗②-5対処がいらないように修正 :バグ改修
たとえばチーム課題として「アラートが多すぎる」を挙げている場合に「不要なアラートが多すぎる」という課題があるならば①-2や①-3の分類にわけて、そこを目指します。
また、「対処すべきアラートが多い」という課題があるならば②-3や②-4の分類とし目指していくと変わってきます。
対処が必要なものは、加えて「緊急度」「インパクト」の考慮も入れます。
「発生1分以内に復旧が必要」となると②-4か②-5を取るべきと判断できるなどアクションが見えてきます。
次のアクションをどうするか?という視点で改善できる形を目指して分類できると、徐々に改善していけるかなと考えています。
サンプル的な内容で恐縮ですが、アラートと故障申告を分類した結果、以下のようなイメージになります。
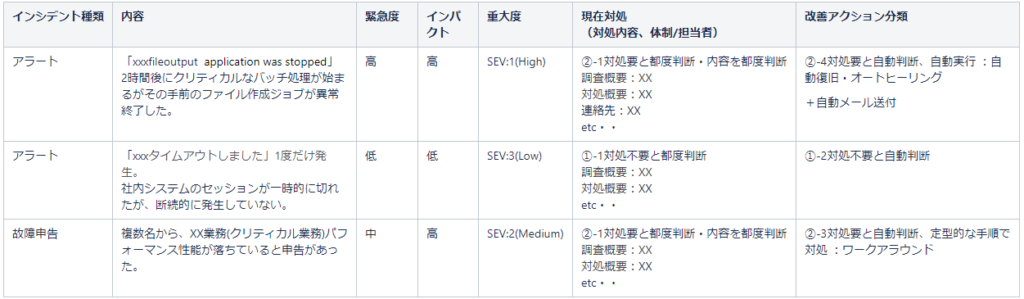
ここまでお読みいただきありがとうございました!
次週は「アラート・故障申告の分類」について触れていきたいと思います。
何かございましたら遠慮なく、感想、コメントいただけますと、幸いでございます。
野村 浩司
最新記事 by 野村 浩司 (全て見る)
- “実践”システム障害対応:12週目:関係者を交えた振り返り - 2022-10-02
- “実践”システム障害対応:11週目:関係者を交えたシステム障害対応訓練 - 2022-10-01
- “実践”システム障害対応:10週目:アクション、判断情報/基準の簡易化 - 2022-09-26

