
システム障害対応の参考になる書籍や最新の考え方を教えて!と思っている方も多いのではないでしょうか。
今回は、私が仮に「システム障害対応のプロセスをゼロから作りたいと考えているんですが、参考になるものを教えてほしい。」と聞かれた際に、簡易的なプロセスならば前回ご紹介した「PagerDuty Incident Response」をおすすめしますが、しっかりプロセスを考え実施することを求めている方へ紹介するなら「システム障害対応の教科書」をおすすめします。
ご紹介書籍
本記事では、システム障害対応の改善を進めるにあたり、参考になった書籍や考え方などをご紹介いたします。
どんな本?
野村総合研究所の木村さんが、2020年4月に出版されています。
野村総合研究所さんといえば、mPLATという運用基盤クラウドサービスで国内シェアNo.1をもたれていて、前身のSenju(千手)からだと1994年から提供開始されているようなので、かなり長い歴史を持たれています。
そのため、システム障害対応の全体プロセスを網羅しており、とてもしっかりした内容で、Tipsに当たるような細かいネタ(本書内で「Point」マークと記載さている)も、かなりたくさんあり具体的なアドバイスが記載されておりました。
どんな方におすすめ?
システム障害時の対応について体系的にしっかりした内容が記載されているため、特に大規模な組織に所属している方などにおすすめです。
保守・運用である程度、長く働かれている方は、教科書的に使いながら自分たちの障害対応プロセスに抜け漏れがないかな?または、新たにプロセスを再構築しようとしている時などに読まれることをおすすめします。
逆におすすめしない方は?
一方で5人程度の小さい組織で開発、保守及び運用を兼務しているような組織の方が読むには少し重すぎるかもしれません。
もちろん様々なパターンを考慮しながら丁寧に記載されていますが、ベースが大規模組織かつ数年レベルで保守・運用を経験している組織へのコンサルティングがベースになっているのではないかなと思います。
気になった箇所と感想
要約されているページは他の方もたくさん出されているので、気になった箇所と感想など記載させていただきます。
2-1章「システム障害の定義」
本書では「リリース後のシステムにおいて、システムの不具合や、ユーザーの操作ミスによって、ユーザー業務に影響が出ている。もしくは出る恐れのあるもの」とされていました。
組織によって定義するべきと本書でも言っているとおり、関係者の共通言語として定義すべきだと思います。
理由は、システム障害の影響極小化のためだと考えます。
システム障害対応のトリガーになる定義であるため、組織やチーム内で意識が違っていると、対応が遅れ知らぬうちに影響範囲が大きくなってしまう可能性があるためです。
そしてこの定義については、顧客接点で定義をした方が良さそうという感想になりました。
ユーザーに影響がまだ出ていなくてもシステム障害の定義に含めた方がいいと思いますし、サードパーティーを利用したシステム構築をしている場合は、サードパーティー側の障害が発生し、提供側に責任がない場合も、顧客が困る事象となるのであれば顧客への連絡は必要となります。
顧客にとっては、システム構築の中身など知る由もなく、ただ使いたいサービスが使えずに困るだけです。
そのため定義として、パッと思いつきですが「顧客が困る事象が出ている。または顧客が困る事象になりそうな可能性の全て。」という感じで、困る事象になる可能性という中には、以下が含まれているとイメージしています。
- システムアラートで気づくもの
- ユーザーからの申告
- 営業担当からのエスカレーション
- サードパーティー側のサービス異常やメンテナンスの情報
最初から完璧な定義はできないので、まずはこの定義についてチームとして会話をする所からはじめていくのが大事かもしれません。
振り返りなどで、定義がブラッシュアップしていき、その結果、いざ顧客が困る事象が発生したとしても、その影響が極小化されていくシステム障害対応ができるようになる道につながると考えています。
2-2章「システム直す≠ 障害対応」
システム障害の目的は、「ユーザーの業務影響を極小化し、早期に業務を復旧させること。」とされていました。
こちらは完全に同意です。
私が開発しているインシデント管理ツールのプロセスの中では「復旧」は「暫定復旧」という言葉を使っています。
システム障害はサービスをいかに早く復旧させて、エンドユーザーが困る時間の長さや影響人数を減らせるかです。
エンジニアからすると、自分が作ったシステムをちゃんと直したいという気持ちから本格復旧しようとしてしまいがちですが、それでは故障経過時間が長くなってしまう事があります。
そこで大事なのがシステム障害をコントロールする、インシデントコマンダーですね。
「顧客が困らないように、早くサービスを暫定復旧するために、今できる最善最適な方法は何か?」という問いを忘れずに優先度を決定し、コントロールしていく必要があると思います。
3.2章「情報の整理・記録と更新」や「障害報告書」など
この章を見て大事だと思ったのは、顧客視点での障害内容でまとめること、そして正確に簡潔にする事です。
これは、「言うは易く行うは難し」ですね…
たとえば「障害内容」「対応の経緯」「直接原因」「復旧対応」などにアプリケーションの処理名や、データベースのテーブル名が記載されていても、知っている人が見ないと何が起きているのか理解できないですし、顧客が何に困っているのかがわからないような内容をたまに見る事があります。
それはそれで実際のエンジニアの調査や復旧には必要な情報レベルなのですが、システム障害が大きいケースは、関係者が多くなるので、どんな関係者でも理解できる情報が必要です。
それが顧客視点で書かれていれば、意識ずれでの手戻りなどが発生せず、影響の極小化につながると考えています。
関係者アクターレイヤーによって連携すべき情報レベルについて、システム障害の運用設計が大事なのかなと思います。
5-1-2章「障害対応フロー図」
大規模な組織で働かれている方は、一度はこのようなサンプルを見た事がある方も少なくはないかと思います。
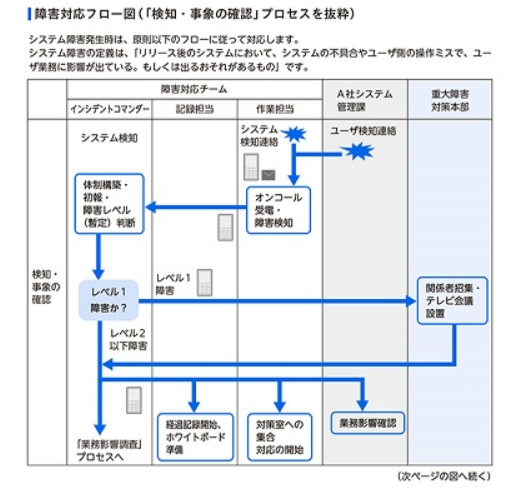
ここで感じたのは、顧客とこのプロセスについて会話できているか否か?で大きく変わりそうだなという感想です。
システム障害時に、顧客がいつどのような情報が欲しいか?顧客はいつどのようなアクションがしたいか?という顧客のニーズによって、プロセスが組まれていたら、準備としては素晴らしいかと思います!
8章内「システム障害対応力の改善と教育」
改善は大事だと思っていても、本来のビジネスを伸ばす業務、新しい開発業務で、なかなか手がつかない方が多くいらっしゃるかと思います…日々お疲れ様でございます。
前回ご紹介した「PagerDuty Incident Response」でも、ポストモーテム(振り返り)の具体的手法の記載がありました。
本書でもポストモーテム例が記載されておりました。
私が振り返りの大事だと思っているポイント
- 時間をあけずにやる
- 迷った事を残す
- 非難を行わない
- 次回使えるようにしておく(ナレッジ化をしておく)
- アクション可能なスモールスタートで改善を開始
この「1.時間をあけずにやる」が、ナレッジを育てるのに非常に大事だと感じています。
お客様には伝えられないかもですが…今回経験したシステム障害インシデントは宝の経験と考え、その場でナレッジとして整理しておけると、必ず次回発生時に品質向上、スペード向上により影響を極小化していけると思います。
貴重なお時間頂き、お読みいただきありがとうございました!
コメント、意見交換、いつでもウェルカムですのでお気軽にご連絡よろしくお願いいたします。
次回も、本のご紹介を引き続きさせていただければと思います。
野村 浩司
最新記事 by 野村 浩司 (全て見る)
- “実践”システム障害対応:12週目:関係者を交えた振り返り - 2022-10-02
- “実践”システム障害対応:11週目:関係者を交えたシステム障害対応訓練 - 2022-10-01
- “実践”システム障害対応:10週目:アクション、判断情報/基準の簡易化 - 2022-09-26

