
12週にわたり「”実践”システム障害対応」と題して、システム障害対応の改善のプロセスを約3か月で実行できるように、各週ごとに何を実践すればよいか?を考えていきたいと思います。
6週目は、システム障害発生時のアクションを判断するための「欲しい情報」は、役割や立場によって視点が変わり、重要視する部分も違うため、事前に認識を合わせておく必要があることをお話させていただきました。
7週目は、「システム障害のフロー整備、システム障害レベルの定義、実現性確認」について考えていきましょう。
システム障害対応フローの設計
1.システム障害対応時に読まなくても覚えられるようにフローは簡易化
皆様の現場では、
- ドキュメントとして”システム障害対応フロー”は、ありますか?
- そのフローは、実際にシステム障害発生時や対応時に本当に参照していますか?
見ているならば素晴らしいと思います!
職場の文化による所も多いかもしれませんが、緊急時に障害対応フローを見るような教育が叩き込まれているかもしれませんが、そのようなチームはとても希少であると考えています。
私が今までの経験の中で知っている限り、システム障害対応フローはシステム障害対応時に全く読まれません。
実際にシステム障害発生時や対応時にこれは読まれるべきドキュメントでしょうか?
もし参照されないなら、作成する必要はあるのでしょうか?
私の意見としては「システム障害対応フローを読むのは平時」であり、そして「システム障害対応時に読まなくても覚えられるようにフローは簡易化」しなければいけないと思っています。
2.システム障害対応フロー作成の目的は”平時の意識合わせ”
「システム障害対応フロー作成を作ろう!」という掛け声はよくあるもので、私も10年システムの保守運用をやっていて毎年1回は聞く言葉です。
一方で10年間、システム障害対応をやったり、インシデントコマンダーとして支援した経験の中で”システム障害対応フロー”を手元に持ちながらやっている人を見たことはありません。
もし皆様の現場に「システム障害対応の意識が合っていない」という課題があるのであれば、”システム障害対応フロー”を作って”平時に意識を合わせ”ることが大事です。
ただ、気を付けたいのは「そのシステム障害対応フローは障害時には読まれない」ことです。
かなり重厚長大で細かいフローを作られる方が多いのですが、システム障害対応時には読んでいる暇は誰にもありません。
そのため、システム障害対応フローは”読まなくても覚えられるよう簡易”にすることが重要です。
STEPとしては以下になります。
- システム障害対応フローを簡易に作成
- 平時にしっかり意識合わせして覚える
- システム障害対応中(実際の障害対応時には読まれない)
- 「振り返り」(課題出し)として対応が終わった後に、再度フローをみんなで確認し頭に叩き込む(これが重要です)
システム障害対応の場面では、臨機応変に対応しなくてはいけない場面もあるかと思います。
大事な事は、顧客やエンドユーザーが困らないよう少しでも影響極小化にするために、何がボトルネックとなったのか?
次回そのボトルネックとなった対応をスムーズに進めるためには、どうしたらいいかを会話し、次回に向けて改善を進める事が大事だと思います。
(繰り返しになりますが、大事な事として、批判しない・責めない事を約束して実施しましょう)
システム障害レベルの決定
皆様の現場の課題として「システム障害が多すぎて困る」や「有識者をもっと早い段階で呼んでおけばよかった」などありませんか?
これらを解決する1つの手段が「システム障害レベルの決定」です。
何故、障害レべルを決めるのかというとシステム障害対応の「体制」を決めるためであると考えています。
何をもって障害レベルを決めるか、以前「“実践”システム障害対応:2週目:アラート・故障申告の分類」で少々触れさせていただきましたが、一般的には「インパクト(影響度)」と「緊急度」になります。
何をもって「インパクト」「緊急度」を決定するか軸を決めておかないとシステム障害のレベルが決まりません。
「インパクト」「緊急度」の分類をそれぞれ大・中・小に分け、その組み合わせで9分類に決まることはありますが、いざシステム障害が発生した際に、具体的な判断軸が無いことで、偉い人の一声で決まり、そこから焦って体制構築するという場面をよく見てきました。
参考になればと思い、具体的な判断軸の例を出していきます。
例1:インパクト:顧客/ユーザー軸で決める
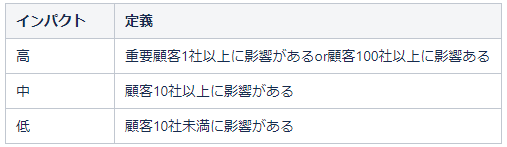
例2:インパクト:業務軸で決める
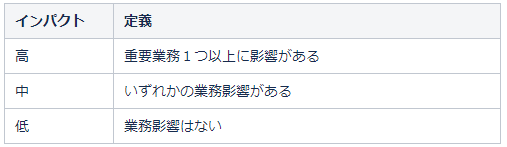
例3:緊急度:時間(リミット時間)で決める

例4:緊急度:処理タイミングで決める
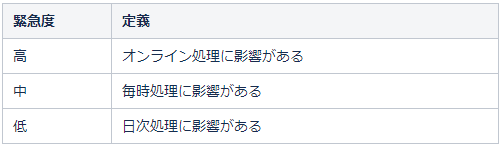
インパクト(影響度)が高い場合は、サービス責任者へ(サービスとして責任を負える方)エスカレーションが必要になってきます。
「どのレベルであれば、誰まで連絡する。」という事が決定すると、いざ故障が起きた時に「どこまで連絡するべきなのか?」と悩まずに済みます。
以下参考イメージです(今後ブラッシュアップしていきます)
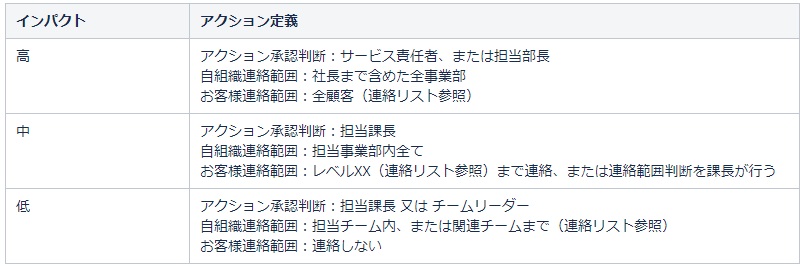
こちらも繰り返しになりますが、方針として「悩んだら連絡する」「連絡を受けた人は、間違っていても相手を非難してはいけない」という文化があれば尚いいと思います。
実現性の確認
前述の例として挙げた、「顧客の何社に影響があるか?」のレベル定義は決めたとしても、システム障害発生直後にその数字は本当にすぐにわかりますか?
システム障害レベルがわからずにその結果、体制が決まらないことで実際の関係者連絡や復旧対処が遅れてしまっては意味がありません。
その場合、もしかしたら「影響有無」という事実がわかってからでないと判断できない形にはせず、「影響の可能性」という形で定義した方がよいかもしれません。
または、システム障害発生直後にすぐわからない状態だから、エラーやログの出し方を工夫して「影響業務は何か?」をすぐにわかるようにするなど、改善が進むかもしれません。
「影響数はどのくらいか?」は、どうやって算出するか調査手順の整理の改善が進むかもしれません。
“ぜひ本当にできるか?“の実現性まで確認しましょう。
こういった定義を決めたとしても、実際のシステム障害発生直後には、なかなか運用されないのがほとんどです。
定義があってもなくとも、偉い人の一声で決まる事実も多いです。
そうであったとしても、その偉い人の判断もインシデントに対するナレッジの一つであり、レベル定義に反映していけるといいですね。
次回は「事業会社・システム会社・ベンダとのミーティング・合意」を予定しています。
ここまで、ご覧いただきありがとうございました!
何か感じる事がございましたら、ご遠慮なくコメントいただけますと幸いです。
野村 浩司
最新記事 by 野村 浩司 (全て見る)
- “実践”システム障害対応:12週目:関係者を交えた振り返り - 2022-10-02
- “実践”システム障害対応:11週目:関係者を交えたシステム障害対応訓練 - 2022-10-01
- “実践”システム障害対応:10週目:アクション、判断情報/基準の簡易化 - 2022-09-26

