
システム障害対応の参考になる書籍や最新の考え方を教えて!と思っている方も多いのではないでしょうか。
本記事では、システム障害対応の改善を進めるにあたり、参考になった書籍や考え方などをご紹介いたします。
今回は2016年頃に話題となったSRE(Site Reliability Engineering)です。
新しい組織の役割分担を考えたい方やシステム運用についてある程度理解している方などにおすすめします。
内容のボリュームが多いため、困っている内容を辞書的に引きながら読むといいと思います。
ご紹介書籍
今回も要約されているページは他の方がたくさん出されているので、個人的な感想など記載させていただきます。
どんな方におすすめ?
Googleのように大企業ではないから必要ない?と思われてしまう方もいるかと思いますが、
この手法の考えで統一されているチームとそうでないチームでは、チームとしての成長や業務効率改善、システム保守安全性に大きな差が出ると思いました。
ざっと本を読んだ感想としては、以下の方が参考になるかと思います。
- 経営層として勝ちつづけられるIT組織にしたい
- インシデントの発生を少なくしたい、発生したとしても早くサービス復旧させたい
- 個人的にスキルを向上させたい(開発、インフラ、保守、運用の方全て)
SREとは
サイトリライアビリティエンジニアリング(SRE)とは、「Googleで培われたシステム管理とサービス運用の方法論です。」
本書には「うまく機能することがわかった一連の慣行、それらの慣行に命を吹き込む信念。仕事上の役割。サービス導入サイクルを安全かつ迅速にするための開発された手法。」等とも書かれております。
下図のように、従来のオンプレやウォーターフォール開発で発生しうるDEVの考えとOPSの考えの違いを課題解決する手段だと思いました。
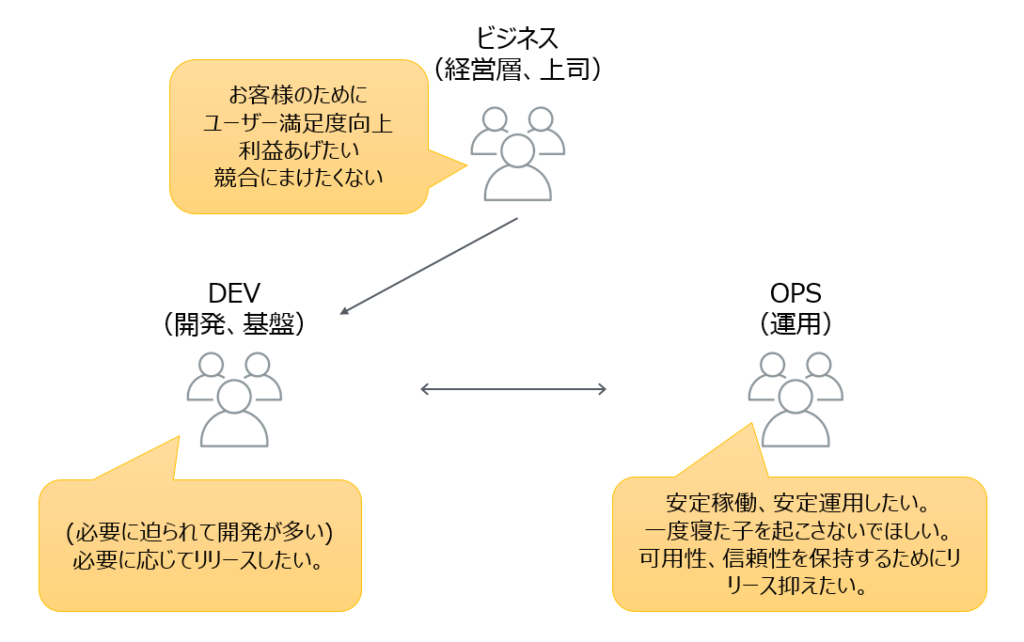
SREって「共通基盤チーム」と似ている?
あくまでも個人の解釈ですが…
長く保守運用をされているチームであれば、一番近しい所は「共通基盤チーム」です。
ただ、この共通基盤チームは、業務チームの指示に従って基盤を変更するのではなく、必要に応じて「APも直しちゃうし、基盤も勝手に直しちゃう」のが違いです。
例えば、事前に監視項目(メトリック)を決めておきます。
webサービスのレスポンスタイムとか、外からの死活監視とか、これらのレベルが下がらないようにする責任をSREチームが負うイメージです。
SREって何がすごいの?
SREの革命的なところは「お客様へのサービス提供に責任を負う」ということです。
組織全体が「素晴らしいサービスで世の中へ貢献したい」という同じ方向を向こうとしている所だと思います。
「Google が掲げる 10 の事実」の1つ目でもある「1. ユーザーに焦点を絞れば、他のものはみな後からついてくる。」という考えが入っていると感じました。
従来のウォーターフォール開発においては、以下のように階層構造で上物がどんどん包含していく形となっていました。
- 共通基盤チームが業務チームへ基盤を提供
- 業務チームが基盤を含めてサービスを作って運用チームへ提供
- 運用チームがアプリ・基盤を含めてお客様へサービス提供
SREの主な機能は2つです。
- 「サービス信頼性向上」 → お客様へのサービス提供(SLI定義から始まり、CUJ決定SLO/SLAを決めて実装する)
- 「トイル(無駄な作業)の削除」 → 原価削減
サービス内容を理解し、SLI/SLO/SLAを決めていく所が今まで顧客から遠い場所にいた所から、ずっと責任感が増して、良いサービスが提供ができそうな予感がしています。
そしてどんどん新しいサービスが生まれる現代では、導入サイクルを素早くしないといけない、その為に クラウド環境/アジャイル開発/ CI/CDは必須といった感じです。
サービス信頼性向上内に含まれるイメージもありましたが、「エラーバジェット(エラー予算)」という考えが面白かったです。
経営の責めと守りのバランスが保てる考えであり、DEVもOPSも顧客のために歩み寄れる仕組みだと思いました。
また本書でも「ポストモーテム」について書かれており、同じような内容と感じましたので、ポストモーテムについては過去ブログも参照いただければと思います。
参考
SREって実際どうなの?
私の個人的な少ない経験の中ではありますが、SREには元基盤チームの方が多く入られる傾向にあると感じています。
世の中で「うまくできました!」って記事は見ますが、私個人的には、まだうまく行っている組織になかなかお目にかかれない印象です。
よくあるパターンは共通基盤チームがSREという名称になったパターンです。
Googleの提唱するSRE組織の役割分担をSREと呼ばれている元基盤チームの組織が担いきるのは、とても難しいと感じました。
元共通基盤チームで、SREの最大の特長でビジネスに直結することに責任を負っていないというのが多い印象です。
SREは、信頼性向上を取り組むにあたって「何に対して」を理解していないと意味がありません。
- 提供しているサービスを理解しているか?
- そのサービスにとって大事な事はなにか?
「名は体を表す」ともいいますので、まずは名前を付けて、そこを目指すって考えも大事だと思います。
導入するには、実際にどうすれば?
本当にSRE組織を目指すならチームや組織全員が思想を理解する所から始め、SREチームの役割を明確にした上で、SREチームがサービス信頼性向上・トイルの削除ができる組織を設計にしないと難しいと思います。
組織・システム設計・運用設計をしっかりした上で、元基盤チームに実施してもらうよりも、業務・基盤・運用の混成チームを作ったほうが現実的ですし、SREは流行ってはいますが、必ずしも正解じゃないので、良い思想はうまく利用しつつ、今までの共通基盤チームであっても私は全然良いのではないかと思います。
SREとしてのインシデント発生した場合は?
「Google が掲げる 10 の事実」の3つ目でもある「3. 遅いより速いほうがいい。」という考えが入っていると感じました。
大事な所は、他の本などと共通点が多い印象です。
- インシデント発生前は、早めの行動を心がけるためにもまず、インシデントの定義を行う。
- インシデント発生したら、1人で責任を背負いこまない。
- インシデント終わったら、ポストモーテムして再発防止を行う。
■1人で責任を背負いこまないための「役割分担」
- IC(インシデントコマンダー)インシデント発生したらOLとCLを指名する。俯瞰で状況を冷静に判断。
- OL(実行作業リード)ICと連携しながらインシデント対応に集中。
- CL(コミュニケーションリード)ステークホルダーに対して最新レポートを提供。
話が少しそれてしまいますが、SREとしての、スキルセットがなかなかハードルが高い印象です。
Googleの求人で「戦略的クラウド エンジニア」という求人がありました。
これがSREの求人か?と思いつつ、スキルとしては以下がそろっている感じです。
- クラウド開発
- インフラスキル
- インシデント対応スキル
保守運用で働く方にとって、これらのスキルセットの人材を目指す事は、現時点ではブルーオーシャンであることは間違いないと思います。
習うは一生で、日々精進しないとですね…
本書はとても分厚く読むのが大変かと思いますが、要約しているサイトや情報は他にたくさんありそうですので、興味がある方は参考にしてみてください。
何かございましたら遠慮なく、感想、コメントいただけますと、幸いでございます。
ここまでお読みいただきありがとうございました!
野村 浩司
最新記事 by 野村 浩司 (全て見る)
- “実践”システム障害対応:12週目:関係者を交えた振り返り - 2022-10-02
- “実践”システム障害対応:11週目:関係者を交えたシステム障害対応訓練 - 2022-10-01
- “実践”システム障害対応:10週目:アクション、判断情報/基準の簡易化 - 2022-09-26

